NOTES on AMP¶
Introduction¶
While Symmetric Multiprocessing (SMP) operating systems allow load balancing of application workload across homogeneous processors present in such AMP SoCs, asymmetric multiprocessing design paradigms are required to leverage parallelism from the heterogeneous cores present in the system.
Heterogeneous multicore SoCs often have one or more general purpose CPUs (for example, dual ARM Cortex A9 cores on Xilinx Zynq) with DSPs and/or smaller CPUs and/or soft IP (on SoCs such as Xilinx Zynq MPSOC). These specialized CPUs, as compared to the general purpose CPUs, are typically dedicated for demand-driven offload of specialized application functionality to achieve maximum system performance.
In AMP systems, it is typical for software running on a master to bring up software/firmware contexts on a remote on a demand-driven basis and communicate with them using IPC mechanisms to offload work during run time.
Why OpenAMP?¶
However, there is no open-source API/software available that provides similar functionality and interfaces for other possible software contexts (RTOS, or bare metal-based applications) running on the remote processor to communicate with the Linux master. Also, AMP applications may require RTOS- or bare metal-based applications to run on the master processor and be able to manage and communicate with various software environments (RTOS, bare metal, or even Linux) on the remote processor. The OpenAMP Framework fills these gaps. It provides the required LCM and IPC infrastructure from the RTOS and bare metal environments with the API conformity and functional symmetry available in the upstream Linux kernel. As in upstream Linux, the OpenAMP Framework's remoteproc and RPMsg infrastructure uses virtio as the transport layer/abstraction.
OpenAMP currently supports the following interactions between operating environments:
- Lifecycle operations - Such as starting and stopping another environment
- Messaging - Sending and receiving messages
- Proxy operations - Remote access to systems services such as file system
Frameworks for IPC and LCM¶
- RPMSG Framework: the RPMsg API enables Inter Processor Communications (IPC) between independent software contexts running on homogeneous or heterogenous cores present in an AMP system.
- remoteproc: this component allows for the Life Cycle Management (LCM) of remote processors from software running on a master processor. The remoteproc API provided by the OpenAMP Framework is compliant with the remoteproc infrastructure present in upstream Linux 3.4.x kernel onward. The Linux remoteproc infrastructure and API was first implemented by Texas Instruments.
The Intercore Communicaiton Protocol¶
In asymmetric multiprocessor systems, the most common way for different cores to cooperate is to use a shared memory-based communication. There are many custom implementations, which means that the considered systems cannot be directly interconnected. Therefore, this document’s aim is to offer a standardization of this communication based on existing components (RPMsg, VirtIO). The whole communication implementation can be separated in three different ISO/OSI layers - Transport (RPMSG), Media Access Control (VirtIO) and Physical layer (Shared Memory). Each of them can be implemented separately and for example multiple implementations of the Transport Layer can share the same implementation of the MAC Layer and the Physical Layer.
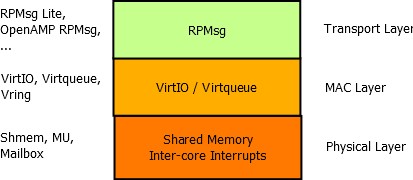
RPMSG Framework (Transport Layer)¶
The RPMsg framework realizes the intercore communicastion. It is an implementation of the VirtIO transport abstraction originally developed for para-virtualization of Linux-based guests for lguest and KVM hypervisors. The rpmsg component uses virtio-provided interfaces to transmit and receive data with its counterpart. As a transport abstraction, virtio provides two key interfaces to upper level users:
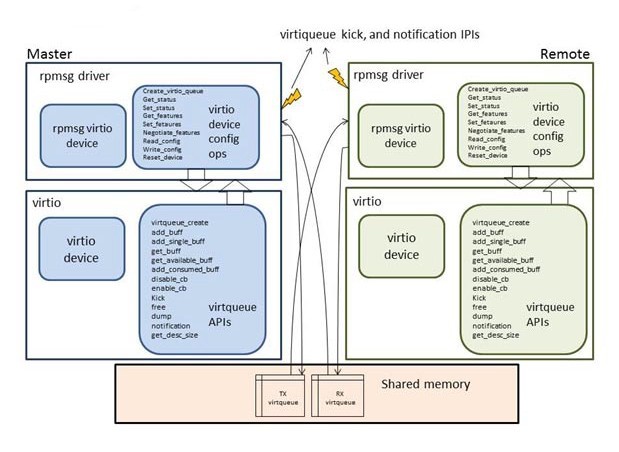
The Linux rpmsg bus driver leverages the virtio implementation in the Linux kernel to enable IPC for Linux in master and remote configurations. An important concept to clarify is the “virtio device” abstraction. This allows a user driver (such as the rpmsg driver) to instantiate its own instance of a virtio device. It also allows for negotiation of the features and functionality supported by this user device by providing implementations of functions in virtio device config operations.
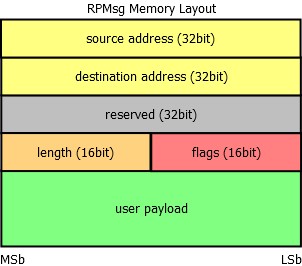
Each RPMsg message is contained in a buffer, which is present in the shared memory. This buffer is pointed to by the address field of a buffer descriptor from vring’s buffer descriptor pool. The first 16 bytes of this buffer are used internally by the transport layer (RPMsg layer). The first word (32bits) is used as an address of the sender or source endpoint, next word is the address of the receiver or destination endpoint. There is a reserved field for alignment reasons (RPMsg header is thus 16 bytes aligned). Last two fields of the header are the length of the payload (16bit) and a 16-bit flags field. The reserved field is not used to transmit data between cores and can be used internally in the RPMsg implementation. The user payload follows the RPMsg header.
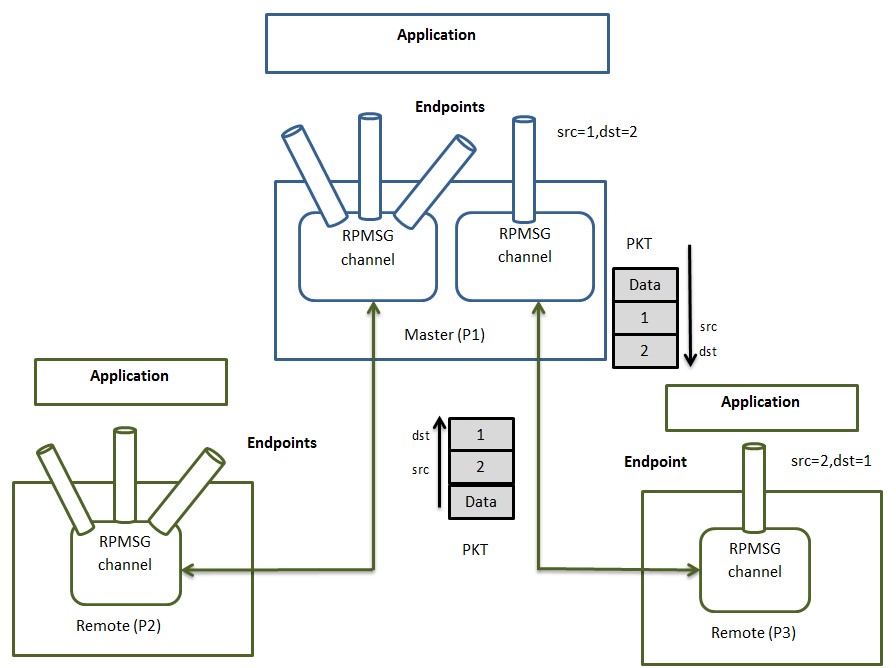
RPMsg Channels¶
Every remote core in RPMsg component is represented by RPMsg device that provides a communication channel between master and remote, hence RPMsg devices are also known as channels. RPMsg channel is identified by the textual name and local source and destination address. The RPMsg framework keeps track of channels using their names.
RPMsg Endpoints¶
RPMsg endpoints provide logical connections on top of RPMsg channel. It allows the user to bind multiple rx callbacks on the same channel.
Every RPMsg endpoint has a unique src address and associated call back function. When an application creates an endpoint with the local address, all the further inbound messages with the destination address equal to local address of endpoint are routed to that callback function. Every channel has a default endpoint which enables applications to communicate without even creating new endpoints.
VirtIO (MAC Layer)¶
The VirtIO implementation in the RPMsg framework (and in Linux) consists of the following:
-
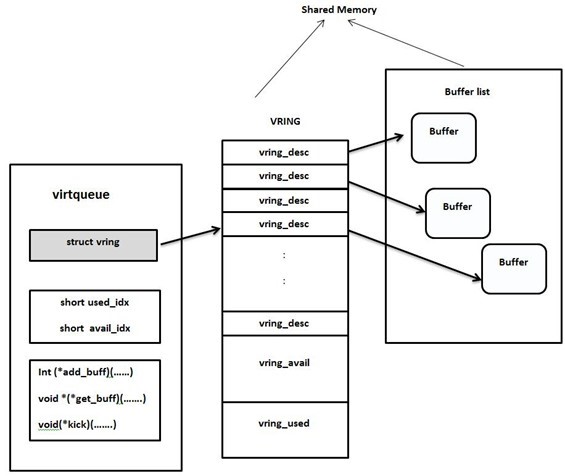
A buffer management component called “VRING,” which is a ring data structure to manage buffer descriptors located in shared memory:
-
A notification mechanism to notify the communicating counterpart the availability of data to processed in the associated VRING. Inter-Processor Interrupts (IPIs) are normally used for notifications.
The virtqueue is a user abstraction that includes the VRING data structure with some supplemental fields, and APIs to allow user drivers to transmit and receive shared memory buffers. Each rpmsg channel contains two virtqueues associated with it: a tx virtqueue for master to uni-directionally transmit data to remote, and a rx virtqueue for remote to uni-directionally transmit data to master.
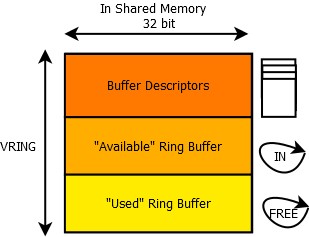
Vring is composed of three elementary parts - buffer descriptor pool, the “available” ring buffer (or input ring buffer) and the “used” ring buffer (or free ring buffer). All three elements are physically stored in the shared memory.
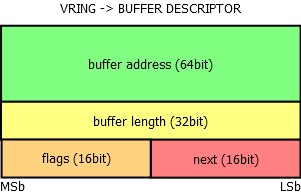
Each buffer descriptor contains a 64-bit buffer address, which holds an address to a buffer stored in the shared memory (as seen physically by the “receiver” or host of this vring), its length as a 32-bit variable, 16-bit flags field and 16-bit link to the next buffer descriptor.
The Master core allocates buffers used for the transmission from the “used” ring buffer of a vring, writes RPMsg Header and application payload to it and then enqueues it to the “avail” ring buffer. The Remote core gets the received RPMsg buffer from the “avail” ring buffer, processes it and then returns it back to the “used” ring buffer. When the Remote core is sending a message to the Master core, “avail” and “used” ring buffers role are swapped.
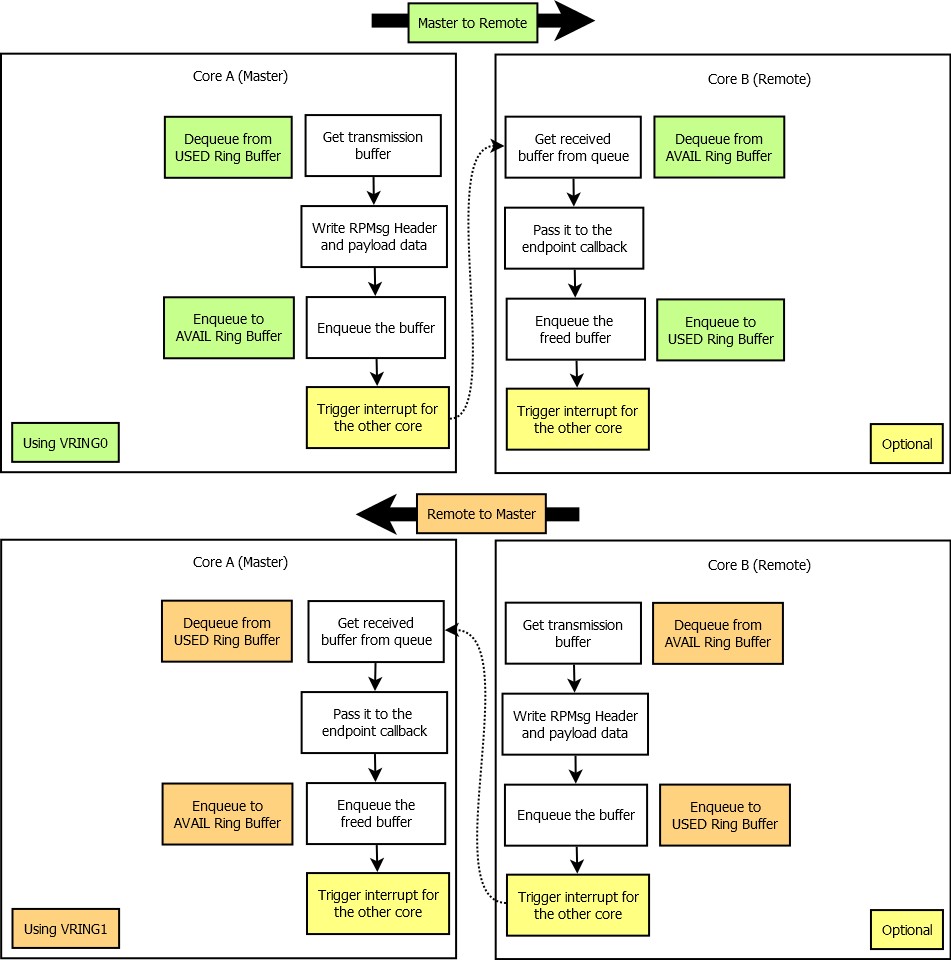
Using VirtIO as a MAC layer is the key part of the whole solution - thanks to this layer, there is no need for inter-core synchronization. This is achieved by a technique called single-writer single-reader circular buffering, which is a data structure enabling multiple asynchronous contexts to interchange data.